Kosmos is now deployed at multiple biopharmaceutical companies powering their R&D, including a major partnership announced today with Incyte. We’ve made a number of improvements to Kosmos and now it feels like a competent colleague that can perform complex long-running tasks. Kosmos is built on a world model and we’ve worked with groups from Stanford, MIT, UCSF, and other institutions to validate that it can propose and validate hypotheses at the level of experts. And today, the first paper underlying the principles of Kosmos was published in Nature where we showed a complete lab-in-the loop discovery campaign from disease to novel therapeutic.
Kosmos runs on a platform that orchestrates its complex workloads in a cloud environment. Building a platform that supports AI agents in executing a nearly limitless array of tasks is a major security challenge, especially in a highly regulated environment. In this blog post, we’ll outline what goes into the engineering of a system like this and how we arrived at our design. I’ll also talk about how we’ve engineered it to work in a more collaborative fashion in secure environments.
We developed Kosmos by trying to replicate the scientific process — generating a hypothesis, proposing an experiment, and updating your beliefs — with something called a “world model.” In AI, a world model is a predictive model developed by agents to predict the effects of their actions in an environment. For Kosmos, the environment is a scientific phenomenon and the world model is the agent’s predictions for the outcome of an experiment. In November, when we first introduced Kosmos, we worked with multiple research groups to test its hypotheses had the same depth and novelty as human hypotheses.
Legacy Kosmos was a beast of an agent. You put in one prompt and it worked for days on building a complex world model for your phenomenon of interest. In our paper, we would ask questions like “why is the entorhinal cortex uniquely vulnerable to aging” and give it a large amount of data. Many were amazed at its depth, but others were surprised that asking Kosmos “can I take two Claritins in one day” would lead to a complex pharmacokinetic model based on scraping patents and clinical trial outcomes.
Now, we’ve taken the world model and put it into a persistent code-writing LLM agent that collaborates during the research process. Kosmos can still review thousands of research papers and patents, including reading the figures and images. But now it will chat with you about the best approach. It will make a website for you showing progress. It can receive and respond to feedback, or send you an email update on new papers that look relevant a day after it gave you the answer.
Kosmos — a code-writing agent
Code-writing agents are the future of AI. Code-writing agents are an LLM with essentially one tool: execute code. These agents write code to make progress and do not require a priori knowledge of the tools required to complete a scientific workflow.
We decided on code-writing agents in late 2025. At first, LLMs couldn’t write code so we used tools. That was the pattern at FutureHouse, where we developed specialized agents like PaperQA and ChemCrow.
As we expanded into more domains, we wanted agents to discover new tools. Ideas have been around like tool servers and MCPs. Legacy Kosmos would route tasks to the specific agent that had the perfect hand-crafted tool set. We also showed how to train an aviary of different scientific agents in our 2024 paper Aviary. In 2026, LLMs have advanced sufficiently in code writing that we can do away with the harness and constraints of tools and simply write code.
This feels so accelerating because there is a convergence in writing good software and equipping agents with the correct tools. We no longer write bespoke tools. We simply have a monorepo for all the integrations and software an AI scientist needs. Instead of AI engineering, we simply write quality code with clear documentation.
A secure, portable, and scalable platform
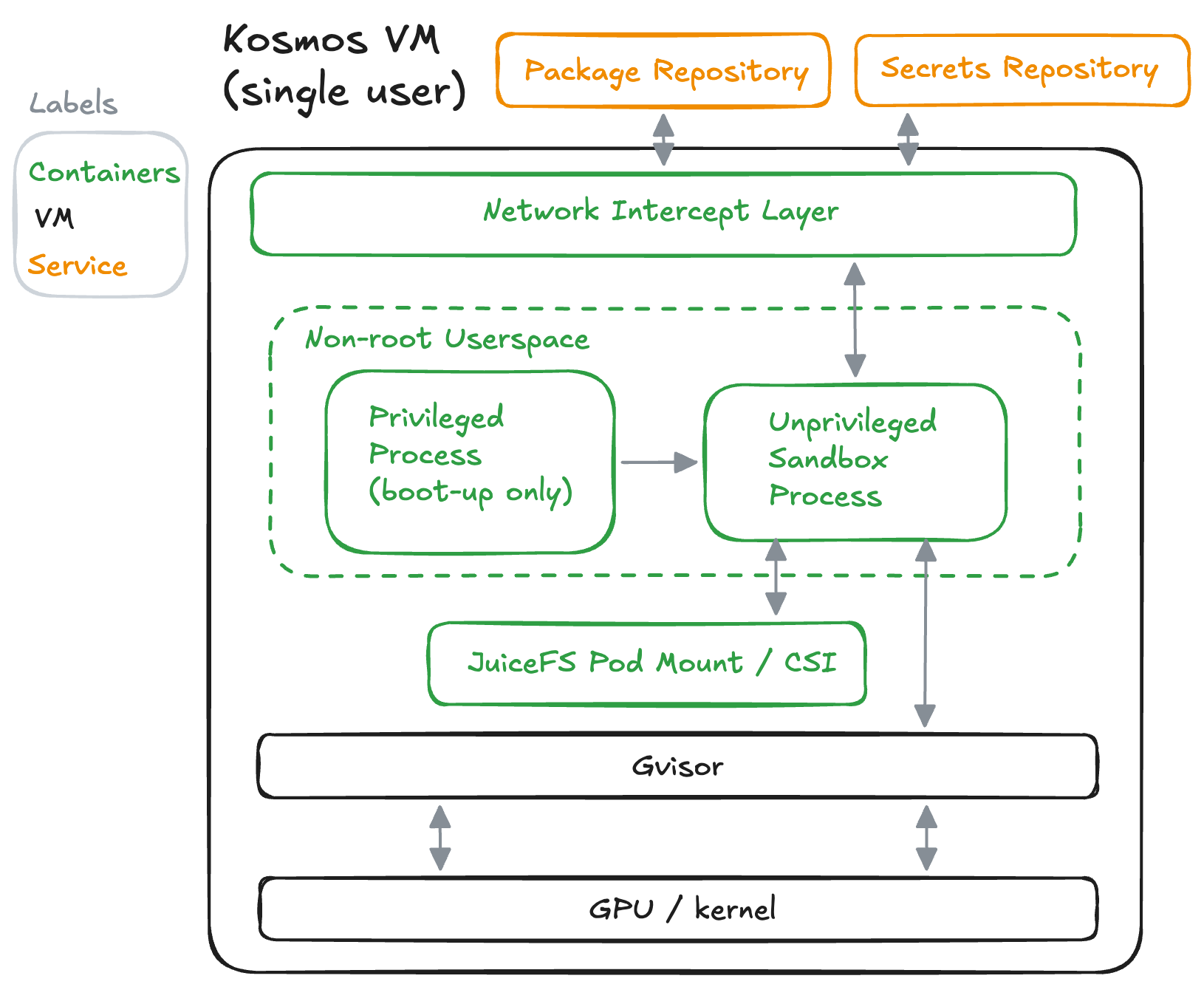
Building a platform that can host agents executing arbitrary code in highly regulated environments is a major engineering challenge. Our platform is portable to partner companies with minimal or no egress and that requires careful design of our agents and platform. These are publicly-traded companies operating in a highly-regulated industry. The benefit is that companies can have our AI Scientist run continuously on their internal data to make new discoveries.
The essential element of code-writing agents is creating a secure and scalable sandbox. A sandbox is an isolated virtual computer that has the software, internet access, and file system required for an agent to do scientific work. That means large amounts of memory and typically an attached GPU.
We use Kubernetes for managing the sandboxes and they are containers on virtual machines. We looked at many solutions for sandboxes but had a few unusual requirements. One is performance. We need serious memory and CPU requirements, and GPUs attached. Many people working on sandboxes have elected to not support GPUs and/or target applications that require minimal memory. Kosmos does large computations. For example, we’ve had Kosmos train graph neural networks to predict how drugs metabolize in the human body. We need GPUs for this.
The second requirement is that we have built our entire platform to be internally deployed on the premises of a partner company. So, no external services can be used and we need a durable self-contained sandbox.
We use a variety of strategies for securing the sandboxes. We use industry standard strategies like gVisor, rootless containers, and single-tenant virtual machines. We also never store secrets or credentials in the sandbox, instead we inject those as requests leave the sandbox. We monitor and rate limit traffic from the sandbox to services. Finally, we’ve elected to self-host all packages that might be installed by the agents to both mitigate supply-chain attacks and minimize egress from the agents.
Making performant sandboxes is an equal challenge to securing them. You need to have persistent filesystems that are fast enough for searching and large enough to support large files used in scientific workflows. We use a distributed filesystem based on cloud buckets that is fast enough to mount and use on multiple agents simultaneously, built on JuiceFS. We also carefully work to bring start-up times to seconds and maintain a warm-pool of ready sandboxes. We further have a heterogenous pool, so that the rightly-scoped hardware is available for specific subagents.
Interacting with Kosmos
When you first talk to Kosmos, it pulls a warm sandbox and chats back. When you ask it to search patents for a precedence, it will call a subagent that is on a different sandbox but a shared filesystem. That allows you to scale the number of subagents independent of Kosmos. So, you could ask for 10 literature searches or explore 10 hypotheses simultaneously. Then, you might ask it to do a protein folding calculation. It will call a protected service and the auth header will be injected by a proxy. That service will have an L4 GPU, which works great for computing folded proteins. During this process, no credentials are accessible to either the agent or the sandbox.
Kosmos may be unfamiliar to people coming from ChatGPT. If you want it to organize your files and subagents into a folder, you just tell it to. It will write the code to reorganize. If you want it to switch to a new topic, you don’t click “new chat.” You say “let’s work on a new project.” If you want to understand its thinking, you say “make a website showing your thinking and results” and it will make a single-page website. Kosmos will idly explore the papers and ideas it has. It can browse social media and find what people are discussing. It requires a mindset shift from old-style chatbots to an AI Scientist that feels like a colleague.
Try it out
You can apply for access to Kosmos today and we’re prioritizing rolling it out to academic research groups. We’ve built a slack integration, so Kosmos can work and collaborate with your whole research group as well. We’d love to hear your feedback!